Розподілена кластеризація
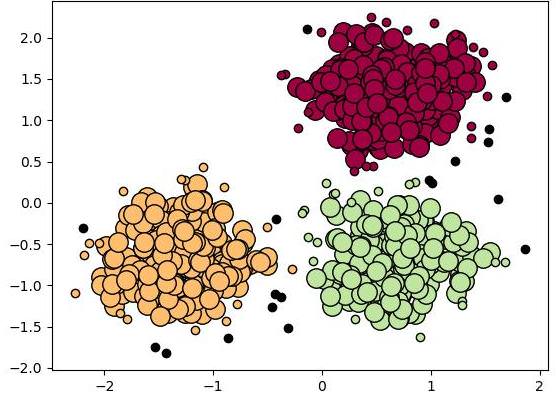
Дані моделі найбільш тісно пов’язані зі статистикою, яка заснована на розподілах. Кластери можуть бути легко визначені як об’єкти, що належать, швидше за все, до одного і того ж розподілу. Зручним властивістю цього підходу є те, що він дуже схожий на спосіб створення штучних наборів даних. Шляхом вибірки випадкових об’єктів з розподілу.
Хоча теоретична основа цих методів чудова, вони страждають від однієї ключової проблеми, відомої як переоснащення, якщо тільки не накладаються обмеження на складність моделі. Більш масштабна зв’язок зазвичай зможе краще пояснити дані, що ускладнює вибір відповідного способу.
Модель гауссових суміші
Даний спосіб використовують різні алгоритми максимізації очікування. Тут набір даних зазвичай моделюється з фіксованим (щоб уникнути перевизначення) числом гаусівських розподілів, які ініціалізуються випадковим чином і параметри яких ітеративне оптимізуються для кращої відповідності набору даних. Ця система буде сходитися до локального оптимуму. Саме тому кілька прогонів можуть давати різні результати. Щоб отримати саму жорстку кластеризацію, об’єкти часто присвоюються гауссовскому розподілу, до якого вони належать. А для більш м’яких груп це не обов’язково.
Кластеризація на основі розподілу створює складні моделі, які в кінцевому рахунку можуть фіксувати кореляцію і залежність між атрибутами. Однак ці алгоритми накладають додатковий тягар на користувача. Для багатьох реальних наборів даних може не бути коротко певної математичної моделі (наприклад, якщо припускати, що гаусівських розподілу розподіл є досить сильним допущенням).