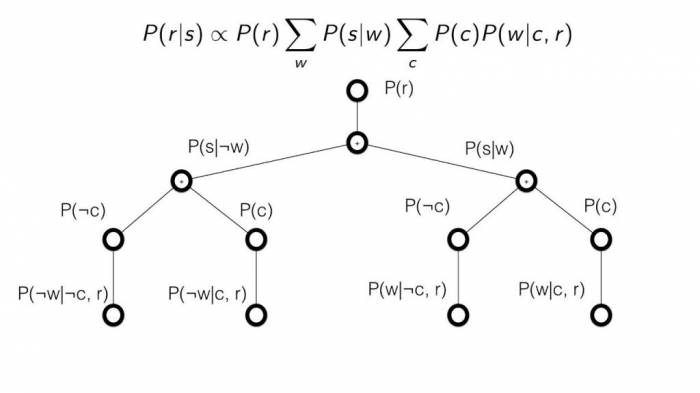
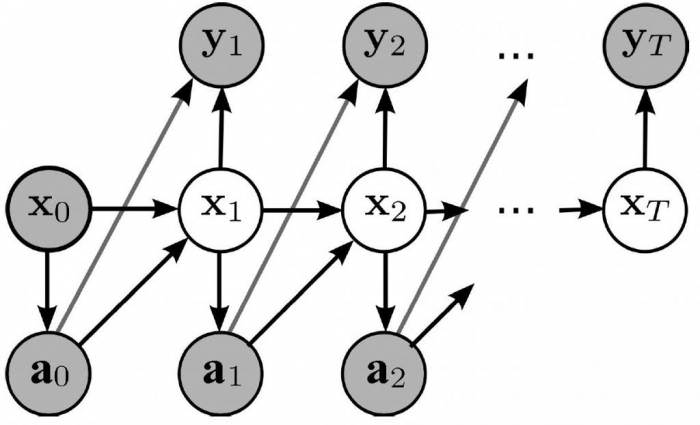
Мережа переконань, рішень, байєсівської (ian) модель або ймовірнісно-орієнтована ациклическая графічна модель – це варіативна схема (тип статистичної моделі), яка представляє набір змінних та їх умовних залежностей через спрямований ациклічний графік (DAG).
Наприклад, байєсова мережа може представляти імовірнісні відносини між захворюваннями і симптомами. Враховуючи останні, мережу можна використовувати для розрахунку можливості наявності різних захворювань. На відео нижче ви можете побачити приклад байєсівської мережі довіри з розрахунками.
Ефективність
Ефективні алгоритми можуть виконувати висновок і навчання в байєсівських мережах. Мережі, які моделюють змінні (наприклад, мовні сигнали або білкові послідовності), називаються динамічними. Узагальнення байєсівських мереж, які можуть представляти і вирішувати задачі в умовах невизначеності, називаються діаграмами впливу.
Суть
Формально байесовские мережі – це групи доступності баз даних, сайти яких представляють змінні в байесовском сенсі: це можуть бути спостережувані величини приховані змінні, невідомі параметри або гіпотези. Тому це дуже цікаво.
Приклад байєсівської мережі
Дві події можуть викликати вологість трави: активний розбризкувач або дощ. Дощ надає безпосередній вплив на використання розпилювача (а саме, що коли йде дощ, розприскувач зазвичай не активний). Ця ситуація може бути змодельована за допомогою байєсівської мережі.
Моделювання
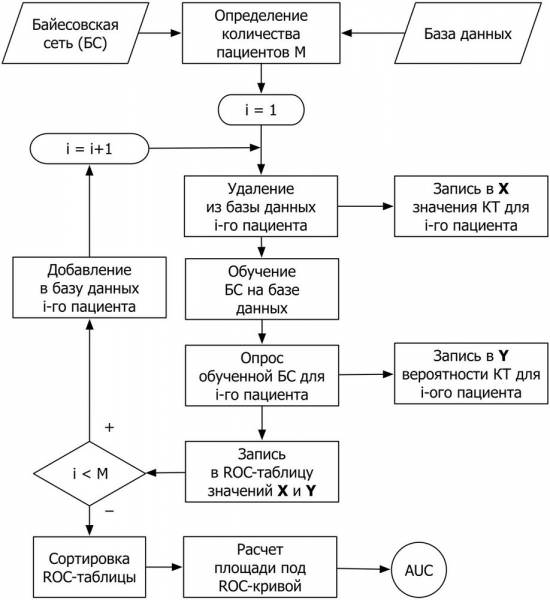
Оскільки байєсова мережа є повною моделлю для її змінних та їх відносин, її можна використовувати для відповіді на імовірнісні запити про них. Наприклад, вона може використовуватися для оновлення знань про стан підмножини змінних, коли спостерігаються інші дані (змінні докази). Цей цікавий процес називається ймовірнісним висновком.
Апостериорный дає універсальну достатню статистику для додатків виявлення при виборі значень для підмножини змінних. Таким чином, даний алгоритм можна вважати механізмом автоматичного застосування теореми Байєса до складним завданням. На картинках у статті ви можете побачити приклади байєсівських мереж довіри.
Методи виведення
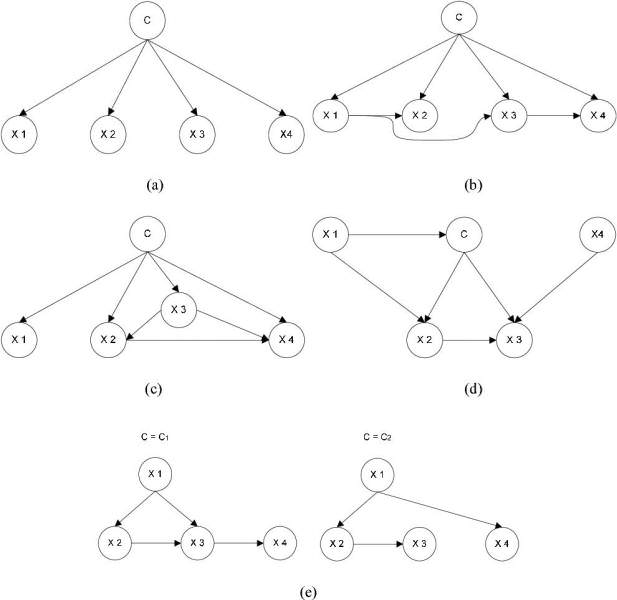
Найбільш поширеними методами точного виводу є: виключення змінних, яке усуває (шляхом інтегрування чи підсумовування) не спостережувані параметри, що не належать до запиту, одну за одною шляхом розподілу суми по продукту.
Поширення “дерева” кліком, який кешує обчислення, так що багато змінні можуть бути запитані за один раз, і нові докази можуть бути поширені швидко; і рекурсивне узгодження і / або пошук, які дозволяють знайти компроміс між простором і часом і відповідають ефективності виключення змінних, коли використовується досить місця.
Всі ці методи мають особливу складність, яка експоненційно залежить від довжини мережі. Найбільш поширеними алгоритмами наближеного виводу є такі способи, як усунення міні-сегментів, циклічне поширення переконань, узагальнене поширення останніх і варіаційні методи.
Робота з мережами
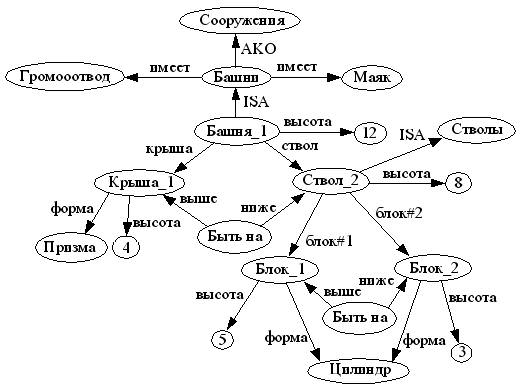
Щоб повністю вказати байєсівську мережу і, таким чином, повністю представити спільний розподіл ймовірностей, необхідно вказати для кожного вузла X розподіл ймовірностей для X, обумовлене батьками X.
Розподіл X умовно за його батькам може мати будь-яку форму. Поширене працювати з дискретними або гауссовыми розподілами, оскільки це спрощує обчислення. Іноді відомі тільки обмеження на розподіл. Потім можна використовувати ентропію для визначення єдиного розподілу, яке має найбільшу ентропію з урахуванням обмежень.
Аналогічно, у конкретному контексті динамічної байєсівської мережі умовне розподіл для тимчасової еволюції прихованого стану зазвичай задається для максимізації швидкості ентропії неявного випадкового процесу.
Пряма максимізація ймовірності (або апостеріорної ймовірності) часто буває складним, враховуючи наявність неспостережуваних змінних. Це особливо характерно для байєсівської мережі прийняття рішень.
Класичний підхід
Класичним підходом до цієї проблеми є алгоритм максимізації очікування, який чергує обчислення очікуваних значень неспостережуваних змінних, що залежать від спостережуваних даних, з максимізацією повної ймовірності (або апостериорного значення), припускаючи, що раніше обчислені очікувані значення вірні. В умовах помірної регулярності цей процес сходиться з максимальним (або максимальним апостериорным) значень параметрів.
Більш повний байєсовський підхід до параметрів полягає в тому, щоб розглядати їх як додаткові неспостережний змінні і обчислювати повне апостеріорне розподіл по всіх вузлів з урахуванням спостережуваних даних, а потім інтегрувати параметри. Цей підхід може бути дорогим і приводити до моделей великого розміру, роблячи класичні підходи до налаштування параметрів більш доступними.
У найпростішому випадку байєсова мережа визначається експертом і потім використовується для виконання висновку. В інших додатках завдання визначення занадто складна для людини. В цьому випадку структура байєсівської нейронної мережі та параметри локальних розподілів повинні бути вивчені серед даних.
Альтернативний метод
Альтернативний метод структурного навчання використовує оптимізаційний пошук. Це вимагає застосування функції оцінки і стратегії пошуку. Поширеним алгоритмом оцінки є апостеріорна ймовірність структури з урахуванням даних навчання, таких як BIC або BDeu.
Необхідний час для вичерпного пошуку, повертає структуру, яка максимізує оцінку, є суперэкспоненциальным по числу змінних. Стратегія локального пошуку вносить поступові зміни, спрямовані на поліпшення оцінки структури. Фрідман і його колеги розглядали використання взаємної інформації між змінними, щоб знайти потрібну структуру. Вони обмежують набір батьківських кандидатів k вузлами і проводять ретельний пошук в них.
Особливо швидкий метод для точного вивчення BN – представити проблему, як задачу оптимізації і вирішити її за допомогою цілочислового програмування. Обмеження ацикличности додаються до цілочисельний програмі (IP) під час рішення у вигляді площин різання. Такий метод може обробляти проблеми з точністю до 100 змінних.

Рішення проблем
Для вирішення проблем з тисячами змінних необхідний інший підхід. Один з них полягає в тому, щоб спочатку вибрати один порядок, а потім знайти оптимальну структуру BN щодо цього порядку. Це передбачає роботу в просторі пошуку можливого упорядкування, що зручно, так як воно менше, ніж простір мережевих структур. Кілька замовлень потім відбираються і оцінюються. Цей метод виявився найкращим доступним в літературі, коли кількість змінних величезна.
Інший метод полягає в тому, щоб зосередитися на підкласі розкладені моделей, для яких MLE мають замкнуту форму. Тоді можна виявити несуперечливу структуру для сотень змінних.
Вивчення байєсівських мереж з обмеженою шириною трьох ліній необхідно для забезпечення точного, піддається трактуванню виведення, оскільки складність останнього в гіршому випадку є експоненціальною по довжині дерева k (згідно з гіпотезою експонентного часу). Тим не менш, як глобальне властивість графа, воно значно збільшує складність процесу навчання. У цьому контексті можна використовувати K-дерево для ефективного навчання.
Розвиток
Розвиток байєсівської мережі довіри часто починається з створення DAG G, такого, що X задовольняє локального властивості Маркова щодо G. Іноді це причинний DAG. Оцінено розподілу умовної ймовірності кожної змінної за її батькам в G. У багатьох випадках, зокрема, коли змінні є дискретними, якщо спільний розподіл X є добутком цих умовних розподілів, то X стає байєсівської мережею щодо G.
Марковское “ковдра вузла” – це безліч вузлів. Марковское ковдру робить вузол незалежним від іншої частини у бланку однойменного сайту і є достатнім знанням для розрахунку його розподілу. X є байєсівської мережею по відношенню до G, якщо кожен вузол умовно незалежний від всіх інших вузлів, враховуючи його марковское ковдру.