Складне завдання: розумний парсинг
Немає нічого простіше», як написати саморазвивающийся парсинг. Алгоритм, який буде адаптуватися в процесі пошуку, не така складна задача. Питання лише в тому як саме застосувати рекурсію, і в яких межах обробляти код HTML-сторінки. Алгоритм пошуку буде розвиватися і адаптуватися до всіх переглянутих сторінок у разі їх зміни.

Інформаційний супровід завдання «розумний парсинг», ймовірно, не стане серйозною проблемою, навіть при відсутності можливості фінансування рекламної компанії. Досить забезпечити розумний алгоритм набором знань з класичних джерел (підручники, книги, статті, науково-дослідні звіти).
Школярі, студенти та наукові працівники – дуже великий ринок для задач пошуку достовірної інформації. Лідери пошукової видачі не задовольняють тут за критеріями об’єктивності і достовірності. Для них головне – об’єм, а не якість результату. Банальне запитання «Чому ліг інтернет, як тільки став Proxmox VE на Debian» не буде мати достовірного відповіді ні Google, ні в Yandex.
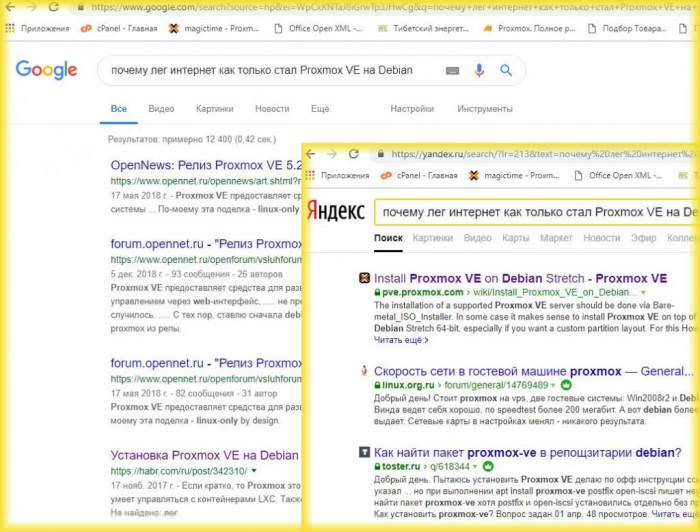
Очевидно, що у вихідному пошуковому запиті немає ні слова про те, як інсталювати продукт, де що знайти і що це таке.
Таким чином, інформаційний супровід проекту «розумний парсинг» не буде простим. Вся справа в тому, що терміни «ліг» і «став» – класичний сленг, а проблема з установкою Proxmox VE ніяк не пов’язана з Інтернетом поза цієї системи віртуальних машин. «Здогадатися» ні Google, Yandex не зможуть. Користувачеві доведеться розбити запит на складові і самостійно вирішити завдання.
Для прийнятного і успішного просування проекту «розумний парсинг» потрібно побудувати його інформаційний супровід таким чином, щоб потенційний споживач розумів: «розумний парсинг» дійсно здатний «розуміти» вихідний запит і розбивати його на потрібні складові.