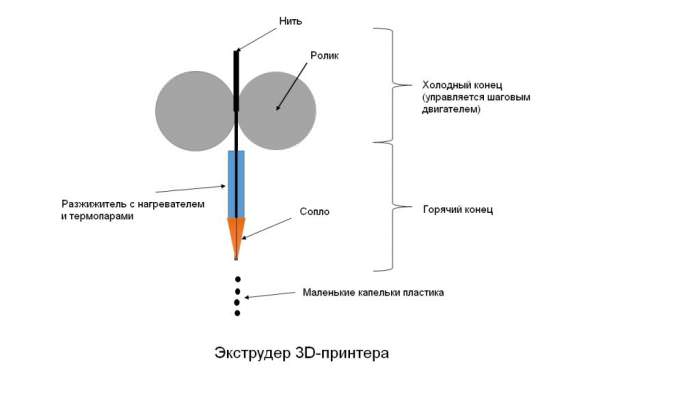
Всі програмісти знають про потенційну загрозу переповнення буфера (buffer) в своїх програмах. Існує багато загроз, пов’язаних з ним, як у новому, так і в старому, незалежно від кількості виконаних виправлень. Зловмисники можуть скористатися такою помилкою, впровадивши код, спеціально призначений для того, щоб викликати переповнення початкової частини набору даних, а потім записати залишилися на адресу пам’яті, суміжний з переповненим.
Дані можуть містити виконуваний код, який дозволить зловмисникам запускати більш великі і складні програми або надавати їм доступ до системи. Помилки дуже важко знайти та виправити, тому що ПО коду складається з мільйонів рядків. Виправлення цих помилок досить складні і, в свою чергу, також схильні до помилок, що ускладнює процес усунення.
Визначення переповнення буфера
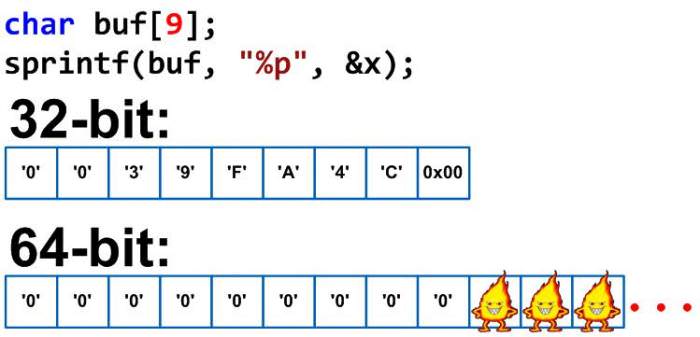
Перш ніж шукати переповнення, потрібно знати, що вона собою являє. Як випливає з назви, ці уразливості пов’язані з буферами або виділенням пам’яті в мовах, які забезпечують прямий низькорівневий доступ до читання і запису.
При застосуванні мов C і Assembler читання або запис таких розподілів не тягне за собою автоматичної перевірки кордонів. У зв’язку з чим, якщо виявлено переповнення стека буфера в даному додатку, не існує перевірки на можливість приміщення числа байтів у розглянутий буфер. В таких випадках програма може «переповнити» його ємність. Це призводить до того, що дані, записувані після наповнення, переписують вміст наступних адрес стеку і зчитують додаткові. Переповнення може статися ненавмисно через помилки користувача.
Буває, що воно викликане тим, що зловмисний суб’єкт надсилає ретельно створений шкідливий введення в програму, яка потім намагається зберегти його в недостатній буфер. Якщо при цьому буде виявлено переповнення стека буфера в даному додатку, надлишкові дані записуються в сусідній, де замінюють будь-які наявні дані.
Зазвичай вони містять покажчик повернення експлуатованої функції – адреса, за якою процес повинен перейти далі. Зловмисник може встановити нові значення, щоб вони вказували на адресу за вибором. Атакуючий зазвичай встановлює нові значення, щоб позначити місце, де розташована корисне навантаження. Це змінює шлях виконання процесу і миттєво передає управління шкідливого коду.
Використання переповнення буфера дозволяє зловмисникові контролювати або завершити роботу процесу або змінювати його внутрішні змінні. Це порушення займає місце в топ-25 найбільш небезпечних програмних помилок світу (2009 CWE/SANS Top 25 Most Dangerous Programming Errors) і визначається як CWE-120 в словнику перерахувань слабких системних місць. Незважаючи на те, що вони добре вивчені, вони продовжують завдавати шкоди популярних програм.
Простий вектор використання буфера
При роботі з вихідним кодом потрібно звернути особливу увагу, де використовуються буфери і модифікуються. Особливо слід відзначити функції, що відносяться до висновку, наданого користувачем або іншим зовнішнім джерелом, оскільки вони забезпечують простий вектор для використання, коли виявлено переповнення стека буфера. Наприклад, коли юзер ставить запитання «так» або «ні», доцільно зберегти рядкові дані користувача в невеликому buffer для рядка «так», як показано в наступному прикладі.
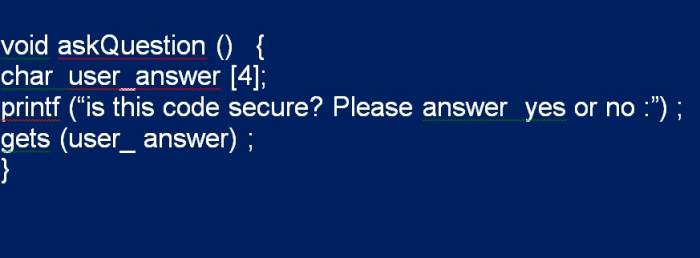
Дивлячись на код, видно, що перевірка кордонів не виконується. Якщо користувач вводить «можливо», то програма аварійно завершувати роботу, а не запитувати у нього відповідь, який записується в buffer незалежно від його довжини. У цьому прикладі, оскільки user answer є єдиною оголошеної змінної, значення в стеку будуть значенням зворотної адреси або місцем в пам’яті, куди програма повернеться після виконання функції ask Question.
Це означає, що якщо юзер вводить чотири байти даних, що достатньо для переповнення буфера команд клієнта, буде дійсний адресу повернення, який буде змінений. Це змусить програму вийти з функції в іншій точці коду, ніж спочатку передбачалося, і може призвести до того, що буде вести себе небезпечним і ненавмисним.
Якщо першим кроком для виявлення переповнення буфера у вихідному коді є розуміння того, як вони працюють, другим етапом є вивчення зовнішнього введення і маніпуляцій з буфером, то третім кроком буде необхідність дізнатися, які функції схильні до цієї проблеми і які можуть діяти як «червоні прапори». Функція gets відмінно підходить для запису за межами наданого їй buffer. Насправді це якість поширюється на все сімейство пов’язаних можливостей, включаючи strcpy, strcmp і printf/sprintf, скрізь, де використовується одна з цих функцій уразливості переповнення.
Видалення з кодової бази
Якщо виявлено переповнення стека буфера у вихідному коді, буде потрібно узгоджене видалення з бази. Для цього треба бути знайомим з безпечними методами роботи. Найпростіший спосіб запобігти ці уразливості, використовувати мову, яка їх не допускає. Мова C має ці уразливості завдяки прямому доступу до пам’яті і відсутності строгої типізації об’єктів. Мови, що не поділяють ці аспекти, зазвичай недоступні. Це Java, Python і .NET, поряд з іншими мовами і платформами, що не вимагають спеціальних перевірок або змін.
Звичайно, не завжди можна повністю змінити мову розробки. В цьому випадку використовують безпечні методи для роботи з переповненням буфера команд. У разі функцій обробки рядків було багато дискусій про те, які методи доступні, які безпечні у використанні, а яких слід уникати. Функції strcpy і strcat копіюють рядок у буфер і додають вміст одного в інший. Ці два методи демонструють небезпечне поведінка, оскільки не перевіряють межі цільового buffer, і виконують запис за межами, якщо для цього достатньо байтів.
Альтернативна захист
Однією з часто пропонованих альтернатив пов’язані версії, які записують у максимальний розмір цільового буфера. На перший погляд це виглядає як ідеальне рішення. На жаль, у цих функцій є невеликий нюанс, який викликає проблеми. При досягненні межі, якщо завершальний символ не поміщається в останній байт, виникають серйозні збої при читанні буфера.

У цьому спрощеному прикладі видно небезпеку рядків, не закінчуються нулем. Коли foo поміщається в normal buffer, він завершується нулем, оскільки має додаткове місце. Це найкращий варіант розвитку подій. Якщо байти в переповнення буфера на стеку будуть в іншому символьному buffer або іншої друкованої рядку, функція друку продовжити читання, поки не буде досягнутий завершальний символ цього рядка.
Недолік полягає в тому, що мова C не надає стандартну, безпечну альтернативу цим функціям. Тим не менше є і позитив – доступність декількох реалізацій для конкретної платформи. OpenBSD надає strlcpy і strlcat, які працюють аналогічно функціям strn, за винятком того, що вони усекают рядок на один символ раніше, щоб звільнити місце для нульового термінатора.
Аналогічно Microsoft надає свої власні безпечні реалізації часто використовуваних функцій обробки рядків: strcpy_s, strcat_s і sprintf_s.
Використання безпечних альтернатив, перерахованих вище, є кращим. Коли це неможливо, виконують ручну перевірку кордонів і нульове завершення при обробці строкових буферів.
Уразливості компіляції

У разі коли небезпечна функція залишає відкриту можливість переповнення буфера C, то не все втрачено. При запуску програми компілятори часто створюють випадкові значення, відомі як канарки (canary), і поміщають їх в стек, тому являють небезпеку. Перевірка значення канарки по відношенню до її первісного значення може визначити, чи відбулося переповнення буфера Windows. Якщо значення було змінено, програма буде закрита або перейде в стан помилки, а не до потенційно зміненим адресою повернення.
Деякі сучасні операційні системи надають додаткову захист від переповнення буфера у вигляді нездійсненних стеків і рандомізації розміщення адресного простору (ASLR). Неисполняемые стеки – запобігання виконанню даних (DEP) – позначають стек, а в деяких випадках інші структури як області, де код не буде виконаний. Це означає, що зловмисник не може впровадити код експлойта в стек і чекати його успішного виконання.
Перед тим як виправити переповнення буфера, розпаковують на ПК ASLR. Він був розроблений для захисту від орієнтованого на повернення програмування як обхідний шлях до нездійсненним стекам, де наявні фрагменти коду об’єднані в ланцюжок на основі зміщення їх адрес.
Він працює шляхом рандомізації областей пам’яті структур, так що їх зміщення складніше визначити. Якщо б ця захист існувала в кінці 1980-х років, хробака Морріса можна було б не допустити. Це пов’язано з тим, що він функціонував частково, заповнюючи буфер в протоколі UNIX finger кодом експлойта, а потім переповнював його, щоб змінити адресу повернення і вказував на заповнений буфер.
ASLR та DEP ускладнюють точне визначення адреси, який потрібно вказати, виконуючи цю область пам’яті повністю неробочою. Іноді уразливість прослизає крізь тріщини, відкриті для атаки переповнення буфера, незважаючи на наявність елементів управління на рівні розробки, компілятора або операційної системи.
Статичний аналіз покриття
У ситуації переповнення buffer є дві вирішальні завдання. По-перше, необхідно визначити вразливість і змінити кодову базу для вирішення проблеми. По-друге, забезпечують заміну всіх версій коду уразливості переповнення буфера. В ідеалі це почнеться з автоматичного оновлення всіх підключених до інтернету систем.
Не можна припускати, що таке оновлення забезпечить достатнє охоплення. Організації або приватні особи можуть використовувати програмне забезпечення в системах з обмеженим доступом до інтернету, вимагають ручного оновлення. Це означає, що новини про оновлення повинні бути поширені серед будь-яких адміністраторів, які можуть використовувати, а патч має бути легкодоступний для завантаження. Створення і поширення виправлень виконують як можна ближче до виявлення уразливості, що забезпечує мінімізацію часу уразливості.
Завдяки використанню безпечних функцій обробки буфера і відповідних функцій безпеки компілятора і операційної системи можна створити надійний захист від переповнення buffer. З урахуванням цих кроків послідовна ідентифікація недоліків є вирішальним кроком для запобігання експлойта.
Комбінування рядків вихідного коду в пошуках потенційних загроз може бути виснажливим. Крім того, завжди є ймовірність, що людські очі можуть пропустити щось важливе. Інструменти статичного аналізу використовуються для забезпечення якості коду, були розроблені спеціально для виявлення уразливості безпеки під час розробки.
Статичний аналіз покриття встановлює “червоні мітки” для потенційних переповнення buffer. Потім їх обробляють і виправляють окремо, щоб не шукати в базі. Ці інструменти в поєднанні з регулярними перевірками і знанням того, як усунути переповнення, дозволяють виявляти і усувати переважна більшість недоліків до завершення розробки ПО.
Виконання атаки через root
Помилки кодування зазвичай є причиною переповнення buffer. Поширені помилки при розробці додатків, які можуть привести до нього, включають в себе нездатність виділити досить великі буфери і відсутність механізму перевірки цих проблем. Такі помилки особливо проблематичні в мовах C/C++, які не мають вбудованої захисту від переповнення і часто є об’єктами атак переповнювання буфера.
У деяких випадках зловмисник впроваджує шкідливий код в пам’ять, яка була пошкоджена через переповнення стека буфера. В інших випадках просто використовують переваги пошкодження сусідній пам’яті. Наприклад, програма, яка запитує пароль користувача для надання йому доступу до системи. У наведеному нижче коді правильний пароль надає привілеї root. Якщо пароль невірний, програма не надає юзеру привілеї.
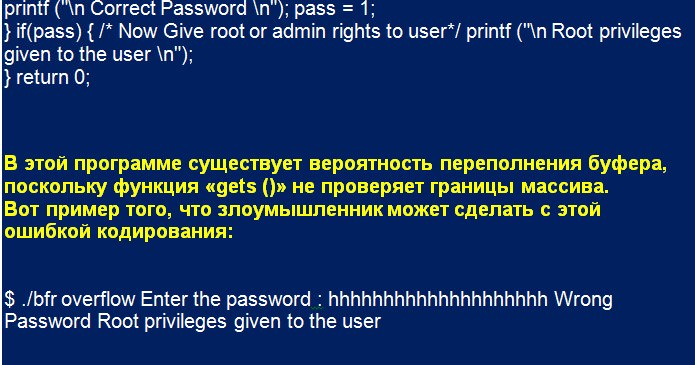
У наведеному прикладі програма надає користувачеві привілеї root, навіть якщо він ввів неправильний пароль. У цьому випадку зловмисник надає вхід, довжина якого більше, ніж може вмістити буфер, створюючи переповнення, перезаписывающего пам’ять цілого числа pass. Тому, незважаючи на невірний пароль, значення pass стає ненульовим, і зловмисник отримує права root.
Атака часовій області зберігання
Буфер являє собою тимчасову область для зберігання даних. Коли програма або системний процес розміщує більше даних ніж було виділено для зберігання, додаткові переповнюються. Це призводить до того, що деякі з них просочуються в інші buffer, пошкоджують або замінюють дані.
При атаці з переповненням додаткові дані містять спеціальні інструкції для дій, призначених хакером або зловмисних користувачем, наприклад, вони викликають відповідь, який пошкоджує файли, змінює дані або розкриває особисту інформацію.
Зловмисник використовує експлойт з переповненням, щоб скористатися програмою, яка очікує введення користувача. Існує два типи переповнення buffer: на основі стека і купи. Засновані на купі важкі для виконання і найменш поширені, при цьому атакують додаток, заповнюючи простір, зарезервоване для програми.
Стек – простір пам’яті, що використовується для зберігання користувальницького введення. Таке переповнення частіше зустрічається у зловмисників, які використовують програми.
Сучасні компілятори зазвичай надають можливість перевірки переповнення під час компіляції/компонування, але під час виконання досить складно перевірити цю проблему без якого-небудь додаткового механізму захисту обробки винятків.

Варіанти роботи програми:
Уразливість існує через переповнення, якщо користувальницький введення argv перевищує 8 байтів. Для 32-бітної системи (4 байта) заповнюють пам’ять подвійним словом (32 біта). Розмір символу становить 1 байт, тому якщо запитати буфер з 5 байтами, система виділить 2 подвійних слова (8 байтів). Ось чому при введенні більше 8 байтів Buffer буде переповнений.
Подібні стандартні функції, які технічно менш уразливі, існують. Наприклад, strncpy (), strncat () і memcpy (). Проблема з цими функціями полягає в тому, що відповідальність за визначення розміру буфера лежить на програміста, а не на компіляторі.
Кожен програміст C/C++ повинен знати проблему перш ніж починати кодування. Багато генеруються проблеми в більшості випадків можуть бути захищені від переповнення.
Небезпеки в C/C++

Користувачі C повинні уникати застосування небезпечних функцій, які не перевіряють кордону, якщо вони не впевнені, що кордони не будуть перевищені. Функції, яких слід уникати в більшості випадків, щоб забезпечити захист, включають функції strcpy. Їх слід замінити такими функціями, як strncpy. Слід уникати використання функції strlen, якщо користувач впевнений, що буде знайдений завершальний символ NIL. Сімейство scanf (): scanf (3), fscanf (3), sscanf (3), vscanf (3), vsscanf (3) і vfscanf (3) – небезпечно для використання, його не застосовують для відправки даних в рядок без контролю максимальної довжини, “формат% s” є особливо поширеним збоєм.
Офіційно snprintf () не є стандартною функцією C класифікації ISO 1990. Ці системи не захищають від переповнення буфера, вони просто викликають sprintf безпосередньо. Відомо, що поточна версія Linux snprintf працює правильно, тобто фактично дотримується встановлену межу. Обчислене значення snprintf () також змінюється.
Версія 2 специфікації Unix (SUS) і стандарт C99 відрізняються тим, що повертає snprintf (). Деякі версії snprintf don’t гарантують, що рядок закінчиться в NIL, а якщо рядок занадто довга, вона взагалі не буде містити NIL. Бібліотека glib має g_snprintf () з послідовною семантикою повернення, завжди закінчується NIL і, що найбільш важливо, завжди враховує довжину буфера.
Переповнення буфера комунікаційного порту
Іноді послідовний порт повідомляє про переповнення buffer. Ця проблема може бути викликана кількома чинниками. До них належать швидкість комп’ютера, швидкість передачі використовуваних даних, розмір FIFO послідовного порту і розмір FIFO пристрою, який передає дані на послідовний порт.
Управління потоком буде чекати, поки в буфері не з’явиться певна кількість байтів, перш ніж процесор відправить повідомлення або сигнал іншого пристрою для припинення передачі. При більш високих швидкостях передачі послідовний порт буде отримувати кілька байтів з моменту досягнення рівня управління потоком буфера і припинення передачі приладу.
Ці додаткові байти будуть більше, якщо процес з високим пріоритетом контролює процесор цілі в реальному часі. Оскільки процес переповнення буфера комунікаційного порту має більш високий пріоритет, ніж переривання VISA, процесор не буде вживати ніяких дій, поки не буде завершено в реальному часі.
Налаштування VISA і Windows за замовчуванням для 16-байтового FIFO складають 14 байтів, залишаючи 2 байта в FIFO, коли пристрій намагається відправити повідомлення від джерела. При більш високих швидкостях передачі на повільних комп’ютерах можливо отримати більше 4 байтів в момент, коли послідовний порт запитує процесор, посилаючи сигнал про припинення передачі.
Щоб вирішити проблему, коли виявлено переповнення стека буфера в Windows 10, потрібно відкрити диспетчер пристроїв. Потім знайти COM-порт, для якого змінюють налаштування, і відкрити властивості. Далі натискають на вкладку «Додатково», з’явиться повзунок, яким змінюють розмір переповнення буфера обміну, щоб UART швидше включив управління потоком.
Значення за замовчуванням у більшості випадків достатньо. Однак якщо надходить помилка переповнення buffer, зменшують значення. Це призведе до того, що більша кількість переривань буде відправлено процесору з уповільненням байтів в UART.
Методи безпечної розробки
Методи безпечної розробки включають регулярне тестування для виявлення та усунення переповнення. Найнадійніший спосіб уникнути або запобігти його використовувати автоматичну захист на рівні мови. Інше виправлення – перевірка кордонів під час виконання, яка запобігає переповнення, автоматично перевіряючи, що дані, записані в буфер, знаходяться в допустимих межах.
Служба Veracode виявляє уразливості коду, такі як переповнення buffer, тому розробники усувають їх до того, як вони будуть використані. Унікальна в галузі запатентована технологія тестування безпеки бінарних статичних додатків (SAST) Veracode аналізує його, включаючи компоненти з відкритим вихідним кодом і сторонні, без необхідності доступу до нього.
SAST доповнює моделювання загроз та огляди коду, що виконуються розробниками, швидше і з меншими витратами виявляючи помилки і упущення в коді за рахунок автоматизації. Як правило, він запускається на ранніх етапах життєвого циклу розробки ПЗ, оскільки простіше і дешевше усувати проблеми, перш ніж приступати до виробничого розгортання.
SAST виявляє критичні уразливості, такі як впровадження SQL, міжсайтовий скриптінг (XSS), помилку переповнення буфера, необроблені стану помилок і потенційні закутки. Крім того, двійкова технологія SAST надає корисну інформацію, яка визначає пріоритети в залежності від серйозності і надає докладну інструкцію по виправленню.
Вразливість переповнення buffer існує вже майже 3 десятиліття, але вона як і раніше обтяжлива. Хакери з усього світу продовжують вважати її своєю тактикою за замовчуванням з-за величезної кількості сприйнятливих веб-додатків. Розробники і програмісти витрачають величезні зусилля для боротьби з цим злом IT-технологій, придумуючи все нові і нові способи.
Основна ідея останнього підходу полягає в реалізації інструменту виправлення, який робить кілька копій адрес повернення в стеку, а потім рандомизирует розташування всіх копій на додаток до кількості. Всі дублікати оновлюються і перевіряються паралельно, так що будь-яка невідповідність між ними вказує на можливу спробу атаки і викликає виключення.