Штучний інтелект та нейроні мережі являють собою неймовірно захоплюючі і потужні методи, засновані на машинному навчанні, які використовуються для вирішення багатьох реальних задач. Найпростіший приклад нейронної мережі – вивчення пунктуації та граматики для автоматичного створення абсолютно нового тексту з виконанням всіх правил орфографії.
Історія нейронної мережі
Вчені в області комп’ютеризації давно намагаються змоделювати людський мозок. В 1943 році Уоррен С. МакКаллох і Уолтер Піттс розробили першу концептуальну модель штучної нейронної мережі. У статті «Логічне числення ідей, що відносяться до нервової активності» вони описали приклад нейронної мережі, концепцію нейрона – єдиної клітини, що живе в загальній мережі, отримує вхідні дані, обробляє їх і генерує вихідні сигнали.
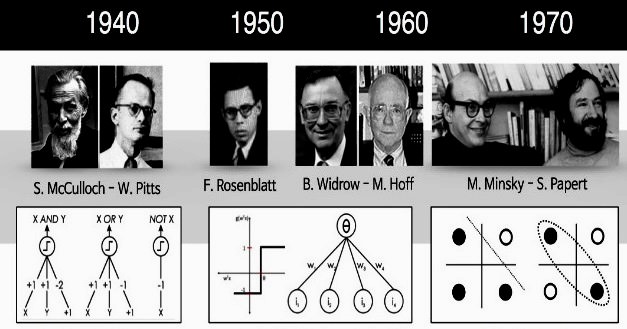
Їх робота, як і багатьох інших вчених, не призначалася для точного опису роботи біологічного мозку. Штучна нейронна мережа була розроблена як обчислювальна модель, що працює за принципом функціонування мозку для вирішення широкого кола завдань.
Очевидно, що є вправи, які просто вирішити для комп’ютера, але важко для людини, наприклад, витяг квадратного кореня з десятизначного числа. Цей приклад нейронна мережа обчислить менш ніж за мілісекунду, а людині потрібні хвилини. З іншого боку, є такі, які неймовірно просто вирішити людині, але не під силу комп’ютера, наприклад, вибрати фон зображення.

Вчені витратили масу часу, досліджуючи і упроваджуючи складні рішення. Найбільш поширений приклад нейронної мережі в обчислювальній техніці – розпізнавання образів. Область застосування варіюється від оптичного розпізнавання символів і фото, надрукованих чи рукописних сканів у цифровий текст до розпізнавання осіб.