Розпізнавання символів в Linux
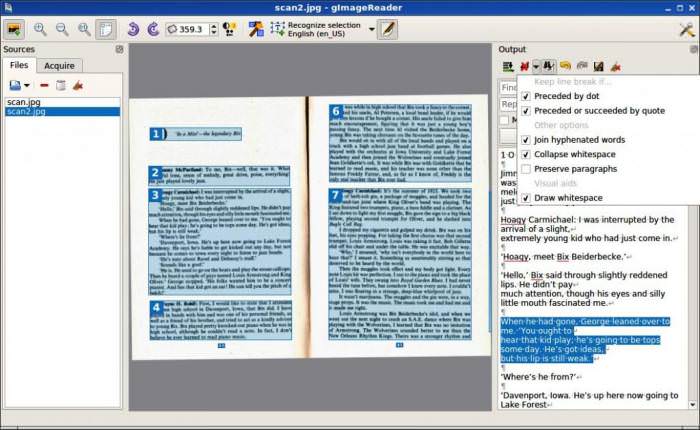
Набір OCRFeeder надає зручний графічний інтерфейс Linux, який в основному є зовнішнім інтерфейсом для деяких зображень, OCR і текстових інструментів таких, як роздруківка або перевірка орфографії. Він не читає символи сам по собі, але замість цього використовує інші програми OCR через так звані налаштування «механізмів розпізнавання». Він має визначені параметри для Tesseract, CuneiForm, GOCR і Ocrad.
Користувачеві потрібно лише встановити в Ubuntu обрані ним движки – один або декілька і потім виявити їх у налаштуваннях Feeder. Можна додати інші движки і змінити ці установки вручну. В одному додатку може бути кілька різних движків. Головне вікно Feeder дозволяє на льоту вибрати, який з них використовувати для конкретної галузі, також є налаштування для вибору одного за замовчуванням. Для вибору мови прочитаного тексту, у випадку з Tesseract і CuneiForm, необхідно додати перемикач «-l» з відповідним кодом мови / скрипта, наприклад, «-l pol» для польського або «-l dan-frak» для данської до налаштувань даного движка
Технологія оптичного розпізнавання друкованих символів “Тессеракт” на початку могла розпізнавати текст англійською мовою, версія 2.x зробила її багатомовною. При необхідності можна встановити більш одного словника. Нові версії оцифровують текст на основі ISO 963-2.
Після успішної установки використовують команду “tesseract>шлях до зображення>базове ім’я вихідного файлу”. Tesseract автоматично додасть вихідного документа розширення “.txt”, можна вказати опцію “-l”, за якою слід код мови. Для версій Tesseract більш ранніх, ніж третя, дуже важливо, щоб зображення було в форматі файлу тегового значення мало розширення “.tif”, а не “.tiff”. Командна рядок повинен виглядати наступним чином:”$ tesseract ~ / input.tif output”.
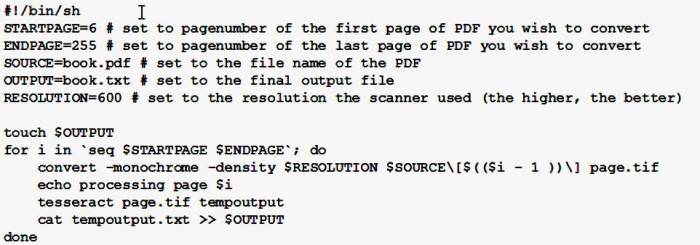
Де “input.tif” – це документ для перетворення, розташований в домашній папці, а “output” – матеріал, який Tesseract створить, як “output.txt”. Часто відскановані тексти зберігаються у вигляді растрового зображення у великому документі PDF. Використовуючи ImageMagick, окремі сторінки можуть бути витягнуті у вигляді файлів TIFF для обробки з Tesseract. Наступний скрипт може допомогти автоматизувати цей процес.
Програма CuneiForm – це ще одна система оптичного розпізнавання тексту, яка була спочатку розроблена і заснована на відкритих джерелах Cognitive Technologies. Версія Windows, яка має власний графічний інтерфейс, може бути запущена з деякими результатами в Wine. Його порт Linux розробляється на Launchpad і хоча в даний час у нього немає власного графічного інтерфейсу, CuneiForm може бути успішно запущений з графічного інтерфейсу OCRFeeder.
Нижче наведено приклад того, як успішно перетворити деякі скріншоти зображень .jpeg дошки оголошень в Інтернеті корисні текстові файли.

Pdfocr – це скрипт, який виконує OCR для багатосторінкових файлів PDF, а також впроваджує його у вигляді текстового шару з можливістю пошуку. Він може використовувати “Тессеракт” або клинопис в якості механізму розпізнавання. Сам скрипт може бути отриманий з Github або з PPA. Щоб запустити команду, прописують у терміналі: “pdfocr -i input.pdf -o output.pdf”.
Технологія OCR не стоїть на місці, в перспективі визнання інтелектуальної системи оптичного розпізнавання символів – ICR. Цей стандарт є передовим. Велика частина ICR має самонавчальну систему, звану нейронною мережею, яка автоматично оновлює базу даних для нових зразків почерку. Вона розширює корисність скануючих пристроїв для цілей обробки документів від розпізнавання друкованого тексту (функція OCR) до рукописних матеріалів і можуть досягати більше 97 % ступеня точності при читанні рукописного матеріалу в структурованих формах.