Технологія OCR (Optical Character Recognition) може бути використана для перетворення друкованої копії документа в електронну версію. Наприклад, якщо сканується багатосторінковий примірник у файл TIFF, то його завантажують в OCR-програму, яка розпізнає текст, і далі переводять в редагований файл. Деякі програми дозволяють сканувати сторінки і перетворювати вміст в документ за один крок.
Хоча технологія спочатку була розроблена для оптичного розпізнавання друкованих символів, вона також може використовуватися для рукописних. Наприклад, поштові служби, такі як USPS, використовують програмне забезпечення OCR для автоматичної обробки листів і посилок, зчитуючи адресу.
Області застосування OCR

OCR розшифровується, як Оптичне Розпізнання Символів. Це широко поширена технологія розпізнавання тексту всередині зображень у вигляді відсканованих документів і фотографій. Технологія використовується для перетворення практично будь-якого типу зображень, що містять письмовий, рукописний або друкований текст у машиночитані текстові дані.
OCR стала популярною на початку 1990-х років при спробі оцифровки історичних матеріалів. З тих пір метод зазнав значні поліпшення, і в даний час забезпечує практично ідеальну точність оптичного розпізнавання символів. Розширені методики, такі як Zonal OCR, використовуються для автоматизації складних робочих процесів на основі перетворення машинописних текстів в цифрові документи. Після того як відсканований матеріал пройшов обробку, текст можна редагувати за допомогою програм, таких як Microsoft Word або Google Docs, які є текстовими редакторами.
До того як з’явилася ця технологія, єдиним варіантом оцифрування друкованих документів був ручний набір тексту. Це не тільки займало багато часу, але і призводило до неточностей і помилок при відтворенні копії. OCR часто використовується в якості «прихованої» технології у багатьох відомих системах та службах, що включають автоматизацію введення даних і індексацію для пошукових систем, автоматичне оптичне розпізнавання символів номерних знаків, а також допомогу сліпим і слабозрячим людям.
Процес визначення точності тексту

Кожен крок процесу OCR важливий для визначення точності остаточного тексту. Він починається з перетворення друкованого документа. Якщо на ньому є сліди, плями і погана контрастність, програмне забезпечення при розпізнаванні буде робити помилки, а результат вийде некоректним. Щоб уникнути цих проблем, можна зробити поліпшену ксерокопію друку.
Перший етап роботи – сканування роздрукованого тексту. Програмне забезпечення OCR працює з файлами зображень. Сканер або хороша цифрова камера створюють чіткі фотокопії документів. Краще перетворити відскановані файли у чорно-білому форматі. Процес є двійковим. За допомогою чорного кольору на картинці відбувається розпізнавання тексту OCR, а білий, в свою чергу, виступає фоном.
Другим етапом є визначення символів. Швидкість цього процесу залежить від використовуваної програми OCR. Більшість з них аналізують кожен елемент один за іншим. Метою програми є визначення знаків, але хороші програми розпізнають не лише текст, але і таблиці, і інші елементи макета.
Процес не ідеальний, так як є багато факторів, які впливають на точність. Які програми призначені для оптичного розпізнавання символів, розглянемо нижче. А користувачу самостійно обирати, що краще. OCR мають вбудовані засоби перевірки правопису і виділяють слова з помилками. Деякі з них настільки складні, що відзначають невідповідність слів і граматичні помилки, користувачеві залишається лише виконати необхідну коригування.
Останній етап – збереження готового документа в потрібному форматі. Якщо додаток не видає необхідний, то можна скористатися численними безкоштовними конвекторами онлайн.
Оптична технологія для Брайля

Технологія Optical Character Recognition (OCR) надає сліпим або слабозрячим людям можливість визначити текст і вимовляти її вголос. При цьому використовується мовний висновок, а також відображається інформація на дисплеї Брайля.
Існує три основних елемента систем оптичного розпізнавання символів: отримання зображення, розпізнавання і читання тексту. Спочатку роздрукований документ захоплюється камерою, потім програмне забезпечення OCR перетворює його в розпізнані символи і слова, а після цього синтезатор в системі вимовляє певний матеріал вголос або відображає на дисплеї Брайля. Інформація може зберігатися в електронному форматі на пристрої, на якому запущено ПО OCR, або в пам’яті автономного устрою.
Процес враховує логічну структуру мови. Система зробить висновок, що, наприклад, союз «цьому» в початку пропозиції є помилкою і повинен читатися, як «це». Вона використовує лексикон і застосовує методи перевірки, аналогічні тим, які використовуються в багатьох текстових редакторах.
Всі системи OCR створюють тимчасові файли, які містять символи і макет сторінки. В деяких системах вони можуть бути перетворені у формати, які можна знайти за допомогою широко використовуваних комп’ютерних додатків, таких як текстовий редактор, електронна таблиця і бази даних.
Вибір програм для розпізнавання тексту

Рекомендується усвідомлено підійти до вибору програмного забезпечення для розпізнавання тексту. Краще провести власне тестування або врахувати думку просунутих користувачів.
Тестування проводять з урахуванням наступних факторів:
Популярний ПО для мобільних пристроїв
OCR відмінно підходить для перенесення тексту з фізичних джерел безпосередньо в цифровий документ. Існують різні типи програм і додатків для настільних і мобільних пристроїв. Вони різні за ціною і мають свої ключові відмінні функції.
Найбільш популярні “Андроїд”-сканери:
Документи Google

Для тих, хто вже знайомий з документами Google, можна використовувати OCR, вбудований в Google Drive. Для досягнення найкращих результатів шрифт повинен бути встановлений на Arial або Times New Roman. Можна поліпшити результат, переконавшись, що скановане зображення має рівномірне освітлення і чітку контрастність. Фотоматеріали можуть оброблятися індивідуально у файлах jpg, png, gif або у багатосторінкових документах PDF. Розширення підтримує більшість мов.
У Google є багато навчальних програм і можливостей хмарної обробки. Багато користувачів вважають, що у сервісу немає достатньо просунутих функцій і опцій. Тим не менш, якщо використовується додаток Google Drive для Android, можна сканувати сторінки прямо з програми, використовуючи камеру на смартфоні. В іншому випадку завантажують документи за допомогою сканера, підключеного до комп’ютера, або будь-яким іншим способом, щоб почати обробку розпізнавання в Google Диску. Для фізичних осіб на Диску Google пропонується безкоштовний рівень зберігання близько 19 ГБ з можливістю розширення до 100 ГБ через Google One за 1,99 дол. США.
Оптичне розпізнавання Abbyy

Abbyy FineReader працює з документами вже давно. Це комплексне рішення, як для бізнесу, так і для звичайних користувачів. У ньому можна отримати всі необхідні функції для витягання змісту текстів з сканера з повною читаністю, акуратно організовані оцифровані матеріали. Крім розпізнавання текстів і перетворення в PDF, Microsoft Office або інші формати, програма також може порівнювати їх, додавати анотації і коментарі.
Abbyy FineReader може конвертувати матеріал в пакетному режимі і обробляти безліч вихідних форматів на 192-х різних мовах. Є супутні мобільні додатки, коли потрібно виконати швидке сканування з телефону.
Програмне забезпечення не найсучасніше, але воно просте, функціональне і відмінно справляється зі своєю роботою. Утиліта має міцну репутацію одного з кращих варіантів в області оптичного розпізнавання символів. Можна скористатися безкоштовною пробною версією. ЗА коштує від 199,99 дол. США за стандартну разову безстрокову ліцензію.
Якщо комусь це здасться дорогим варіантом, можна скористатися хорошою альтернативою ABBYY FineReader – онлайн версією. Вона обмежена тим, що дозволяє сканувати тільки 10 сторінок в місяць. Але поставляється з усіма іншими функціями преміум-версії. Буде потрібно реєстрація, щоб отримати доступ. Вона підтримує дуже багато форматів вхідних файлів, і можна вибрати вихідні, такі як PDF, Word, Excel, PowerPoint і e-Pub.
Хмарний сервіс Adobe Acrobat

Adobe Acrobat відповідає всім вимогам і пропонує вражаючий список можливостей і опцій, хоча ціна дещо крутіше, ніж у конкурентів. Для всіх функцій оптичного розпізнавання тексту вибирають Pro версію Adobe Acrobat. DC означає «Хмара документів», і досить чітко інтегрується з хмарним рішенням Adobe, якщо потрібно отримати доступ до своїх файлів з будь-якого комп’ютера. Також є проста і безшовна інтеграція зі всіма іншими сервісами Adobe, наприклад, таким як Photoshop.
Якщо користувач вирішить оплатити Pro версію Adobe Acrobat DC, він отримає всі інструменти розпізнавання тексту, можливість добавляти коментарі та відгуки до змісту, спеціалізований сервіс для сканування таблиць, можливість швидкого порівняння двох документів разом. Матеріали можна редагувати прямо на екрані через кілька секунд після їх сканування.
Знак Adobe гарантує певний рівень якості, і користувачі вражені інтуїтивністю і можливостями Adobe Acrobat DC. Підписка на сервіс починається з 12,99 дол. США.
Найкраще безкоштовне програмне забезпечення
Free OCR to Word – це найкраще безкоштовне програмне забезпечення для оптичного розпізнавання символів, що використовує новітні механізми. Tesseract – найпотужніший інструмент для даного типу і вважається одним з найбільш точних методів. Програма підтримує кілька форматів зображень і TIFF декількох сторінок. Цей сервіс може бути використаний абсолютно безкоштовно для вилучення тексту з наданого фотоматеріалу.
Двигун Tesseract був спочатку розроблений Hewlett Packard Labs в 1985-1994 роках. Деякі зміни були внесені до нього у 1996 році. У 1995 році він був включений в трійку найкращих механізмів розпізнавання. Він працює з Windows, Linux і Mac OS X. FreeOCR може обробляти зображення, що мають багатоколонний та багатомовний текст. Він обробляє формати PDF і підтримує пристрої TWAIN такі, як сканери, має широко розповсюджений інтерфейс з подвійним вікном, налаштування якого легко зрозуміти.
Free OCR to Word може заощадити багато часу без необхідності повторного введення вже написаного твору. Програма бере документ, відсканований об’єкт або зображення і перетворює його в читаний, редагований і точний матеріал. Можна безкоштовно завантажити у Word. OCR to Word оптимізований для роботи з усіма типами сканерів і має рейтинг точності 98 %, сучасний інтерфейс, який дозволяє легко отримати доступ до всіх завдань, є функції повороту на випадок, якщо фото не поміщається на екрані правильно. ЗА витягує текст з захоплених знімків за допомогою смартфонів або цифрових камер з високою точністю і якістю.
Розпізнавання символів в Linux
Набір OCRFeeder надає зручний графічний інтерфейс Linux, який в основному є зовнішнім інтерфейсом для деяких зображень, OCR і текстових інструментів таких, як роздруківка або перевірка орфографії. Він не читає символи сам по собі, але замість цього використовує інші програми OCR через так звані налаштування «механізмів розпізнавання». Він має визначені параметри для Tesseract, CuneiForm, GOCR і Ocrad.
Користувачеві потрібно лише встановити в Ubuntu обрані ним движки – один або декілька і потім виявити їх у налаштуваннях Feeder. Можна додати інші движки і змінити ці установки вручну. В одному додатку може бути кілька різних движків. Головне вікно Feeder дозволяє на льоту вибрати, який з них використовувати для конкретної галузі, також є налаштування для вибору одного за замовчуванням. Для вибору мови прочитаного тексту, у випадку з Tesseract і CuneiForm, необхідно додати перемикач «-l» з відповідним кодом мови / скрипта, наприклад, «-l pol» для польського або «-l dan-frak» для данської до налаштувань даного движка
Технологія оптичного розпізнавання друкованих символів “Тессеракт” на початку могла розпізнавати текст англійською мовою, версія 2.x зробила її багатомовною. При необхідності можна встановити більш одного словника. Нові версії оцифровують текст на основі ISO 963-2.
Після успішної установки використовують команду “tesseract>шлях до зображення>базове ім’я вихідного файлу”. Tesseract автоматично додасть вихідного документа розширення “.txt”, можна вказати опцію “-l”, за якою слід код мови. Для версій Tesseract більш ранніх, ніж третя, дуже важливо, щоб зображення було в форматі файлу тегового значення мало розширення “.tif”, а не “.tiff”. Командна рядок повинен виглядати наступним чином:”$ tesseract ~ / input.tif output”.
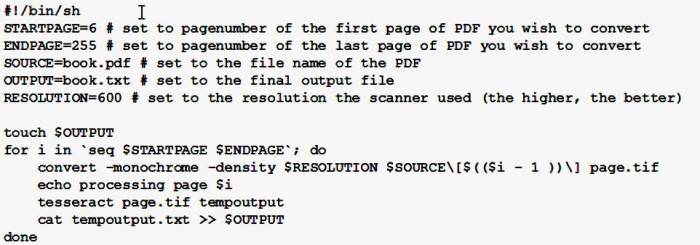
Де “input.tif” – це документ для перетворення, розташований в домашній папці, а “output” – матеріал, який Tesseract створить, як “output.txt”. Часто відскановані тексти зберігаються у вигляді растрового зображення у великому документі PDF. Використовуючи ImageMagick, окремі сторінки можуть бути витягнуті у вигляді файлів TIFF для обробки з Tesseract. Наступний скрипт може допомогти автоматизувати цей процес.
Програма CuneiForm – це ще одна система оптичного розпізнавання тексту, яка була спочатку розроблена і заснована на відкритих джерелах Cognitive Technologies. Версія Windows, яка має власний графічний інтерфейс, може бути запущена з деякими результатами в Wine. Його порт Linux розробляється на Launchpad і хоча в даний час у нього немає власного графічного інтерфейсу, CuneiForm може бути успішно запущений з графічного інтерфейсу OCRFeeder.
Нижче наведено приклад того, як успішно перетворити деякі скріншоти зображень .jpeg дошки оголошень в Інтернеті корисні текстові файли.

Pdfocr – це скрипт, який виконує OCR для багатосторінкових файлів PDF, а також впроваджує його у вигляді текстового шару з можливістю пошуку. Він може використовувати “Тессеракт” або клинопис в якості механізму розпізнавання. Сам скрипт може бути отриманий з Github або з PPA. Щоб запустити команду, прописують у терміналі: “pdfocr -i input.pdf -o output.pdf”.
Технологія OCR не стоїть на місці, в перспективі визнання інтелектуальної системи оптичного розпізнавання символів – ICR. Цей стандарт є передовим. Велика частина ICR має самонавчальну систему, звану нейронною мережею, яка автоматично оновлює базу даних для нових зразків почерку. Вона розширює корисність скануючих пристроїв для цілей обробки документів від розпізнавання друкованого тексту (функція OCR) до рукописних матеріалів і можуть досягати більше 97 % ступеня точності при читанні рукописного матеріалу в структурованих формах.