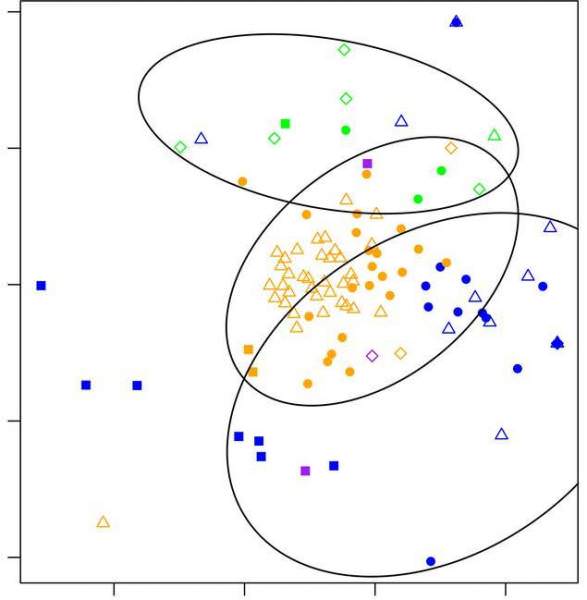
Багатовимірне шкалювання (ДН) – це засіб візуалізації рівня подібності окремих випадків набору даних. Він відноситься до набору пов’язаних методів ординації, використовуваних при візуалізації інформації, зокрема, для відображення інформації, що міститься в матриці відстаней. Це форма нелінійного зменшення розмірності. Алгоритм MDS спрямований на розміщення кожного об’єкта в N-мірному просторі таким чином, щоб відстані між об’єктами зберігалися як можна краще. Потім кожному об’єкту присвоюють координати в кожному з N вимірювань.
Кількість вимірювань графіка MDS може перевищувати 2 і вказується апріорі. Вибір N = 2 оптимізує розташування об’єктів для двовимірної діаграми розсіювання. Приклади багатовимірного шкалювання ви можете побачити на картинках в статті. Особливо показові приклади з маркуванням російською мовою.